


Interested In Comparing Your Ability To Respond
To Cyber Incidents To Others’?
This blog provides details of a noteworthy cyber incident, and data about how a variety of organizations would manage it. This information comes from a crowdsourced tabletop exercise led by our Strategic Advisory team. You’ll find poll results and discussions about the good, bad, and gaps.
Why are we sharing this data?
In many small/medium businesses, incident response plans either don’t exist, are lacking, or don’t often get stress tested. This, in spite of the fact that the Ponemon Institute found that lost business costs due to data breaches averaged $1.42 million in 2022.
This article also provides some insights on how an Incident Response Tabletop Exercise works. Read on if you’re curious about how your cyber incident response measures up.
Scenario 1: Supply Chain Compromise
We posed the first question to replicate a trending incident.
“You apply a routine, vendor-provided update to your Enterprise Resource Planning (ERP) application. Things seem to be working as expected immediately after the change. The system is put back into production and is processing transactions.
Several days later, you are notified by the vendor that they were compromised and that this recent patch contains exploit code….”
We know this is an unfair but all too common situation. Ever since SolarWinds, adversaries have purposefully infiltrated the systems, that when weaponized, impact the most downstream organizations. Very recently, well-meaning vendors have created their own problems.
Question 1: Would You Know Something Is Wrong?

Less than 25% of respondents felt they would get early warning about the incident.
In this case, tools matter. That’s why 25% of participants with a Security Information Event Management (SIEM) and User and Entity Behavior Analysis (UEBA) believe they’d have a chance of detecting the incident.
75% of respondents are right not to be overconfident.
Why?
In the infamous SolarWinds incident, the first people to ID the issue wasn’t SolarWinds. It was discovered by the SecOps engineers at the cyber monitoring firm FireEye (now part of Google). As SolarWinds users, they only found the breach after exhausting every other lead. They’d looked everywhere else before finally decompiling SolarWinds’ code (18000 files, 3500 executable files, and 1M lines of assembly code) to find the implant.
After thousands of hours of looking at every other place, FireEye’s CEO described the implant as “The last place, not the first place, you’d look” to ID the benign looking traffic. This was months after they started looking, after picking up a stealthy IP session to an unknown server on the Internet, posing as a SolarWinds server.
In other words, if it took cyber pros months to detect the issue, your SIEM and UEBA need to be uber-aware to notice such stealthy changes. It’s a safer approach to assume breach every time you patch your servers and applications.
Question 2: What Would You Do First?
Now that responders are aware of an issue, they responded in the following way:
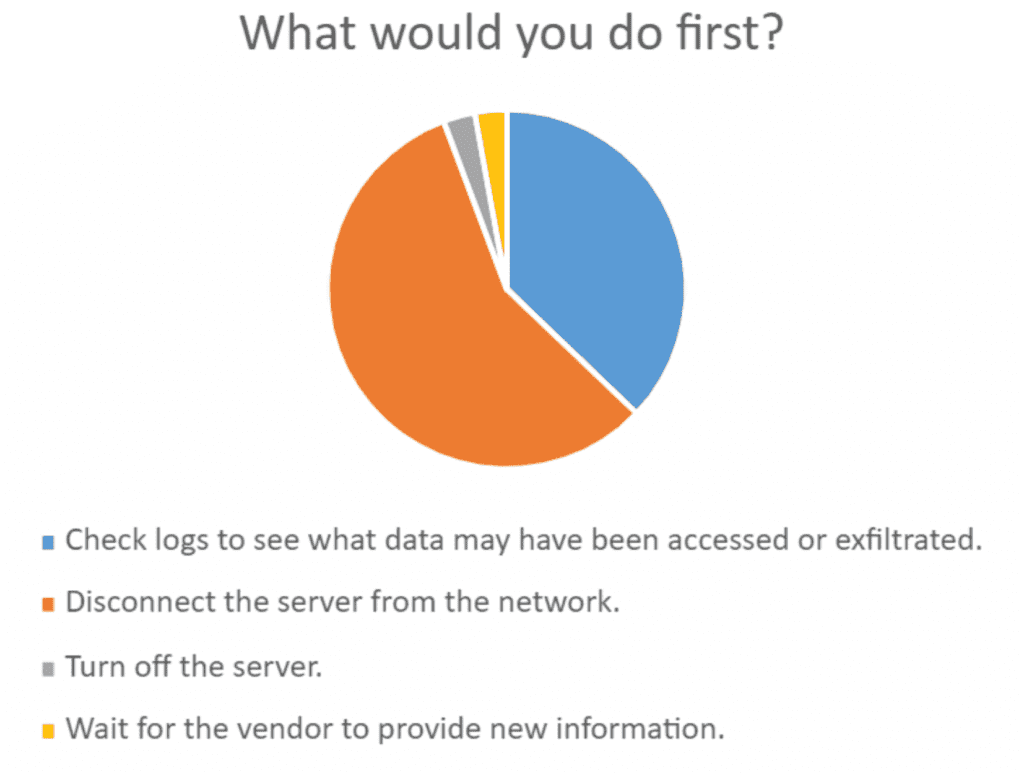
Those that disconnect the server right away would be wise to at least ask for business leadership’s approval for isolating a critical system. One participant wisely asked, “Where is the option to “Initiate the Incident Response Plan?”
In a real tabletop exercise, subsequent follow up questions would be asked:
- Who would authorize the disconnection? And how quickly do you make this decision?
- Who would execute the disconnection (and how)? Could they maintain a diagnostic connection, and via what means? (i.e., terminal server, KVM?)
- Who would alert the user community and other stakeholders (partners, customers)? What is the message at this point in time?
Question 3: Do You Have A Tool To Analyze The Logs?
A good tabletop exercise goes with the flow. Since a substantial number of respondents said they’d check logs, we followed up with a question of, “how?”
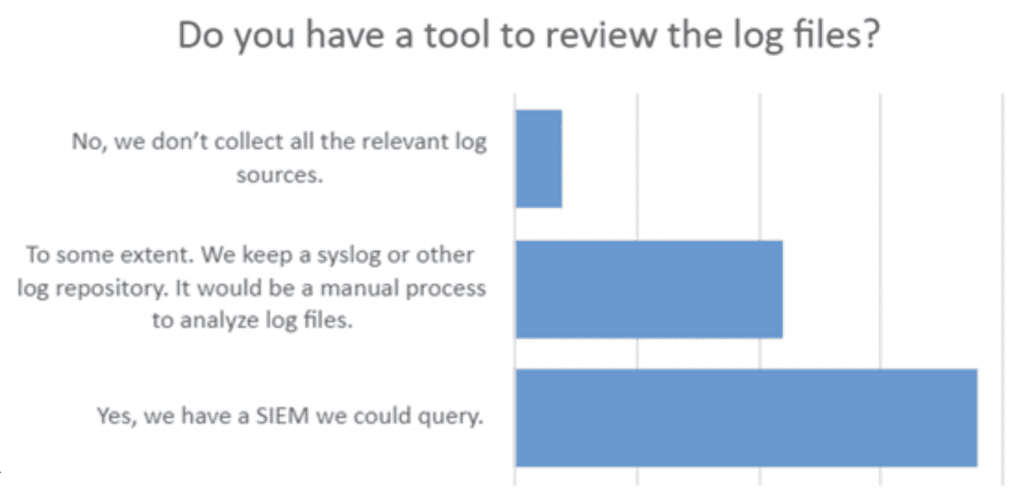
Tabletop leaders would then ask some logical steps about the expected process….
- If a manual review is necessary, who would do that work? Are they on call?
- Do they know the ERP application? What would the analysts be looking for?
- How would they know what was anomalous vs. what was normal?
- Would the SIEM know what is normal vs anomalous? How can you be sure?
The questions posed by the tabletop leader can (and should) become harder. They should weave between people, process, and technology/tools. All parts of the incident response should be covered, including business impacts, stakeholder communication, and potentially restoration (to a known/good version).
Which led to question 4…..
Question 4: Do You Have A Way To Roll Back The Change Back To Before The Compromise And Re-Run All The Transactions That Were Using The Compromised Code?
43% of respondents said they do, meaning 57% have a crucial decision to make:
a. Leave the server running on a known/compromised version
or
b. Continue to leave it in a disconnected state, with severe business impact
We couldn’t see the faces of our participants, but we’d envision a few discomforted looks! That’s OK! It’s better to know (and communicate) to management so that you can get resources to close such gaps, or at least set proper expectations.
Question 5: Where Does The Process For Responding To This Incident Exist:
No matter how the previous questions have gone, our final question for any incident is asking where the process for responding is documented.
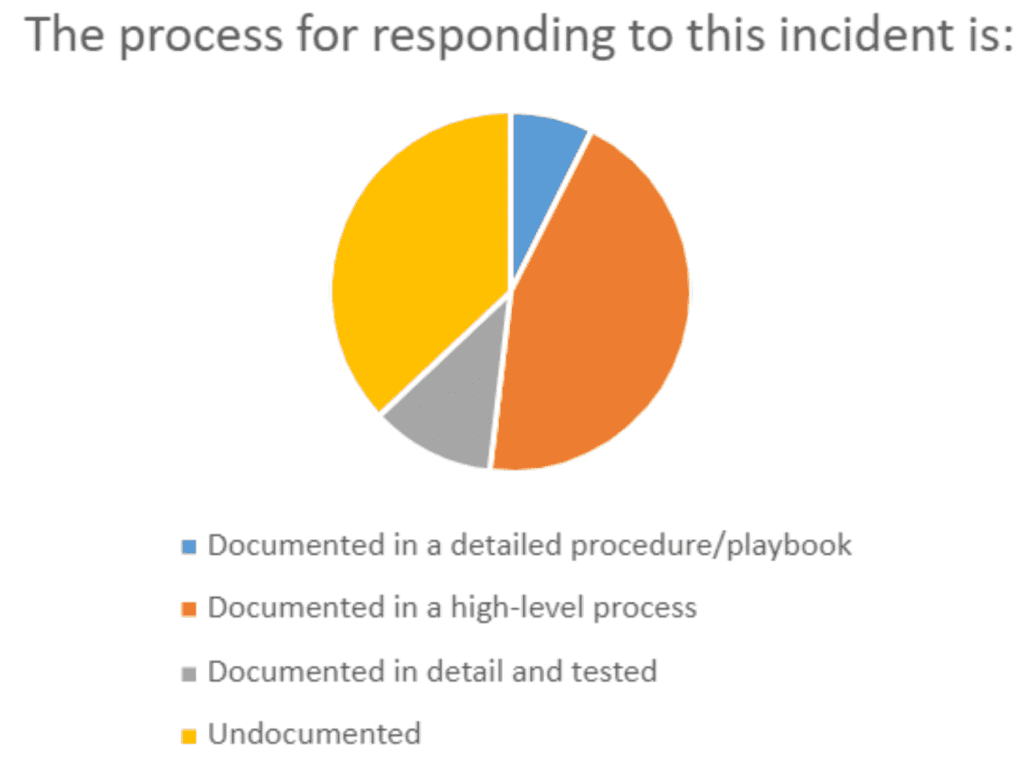
Props go to the participants that take their ERP seriously enough to document a playbook!
Even more applause to those who have tested the recovery!
For those well-prepared organizations, a good tabletop coordinator would typically inject a curveball, an unforeseen and potentially bizarre situation. In this case, had our collective audience passed the previous tests, we’d ask a 6th question: “The ERP compromise is reported on the national news the next day, and your #1 Salesperson is asked by your #1 customer how you are handling it. What’s next?”
More than we’d like to admit, we hear that incident responders store their plans “in their heads.” They’re not in a binder or offline soft copy. They’re neither known nor accessible by their peers or successors. We trust that those folks now have some proof to management that investing time and resources in such efforts is necessary.
Bonus Question: What Did You Learn?
At the end of each scenario, it helps to ask all participants to share their thoughts. Some of our respondents obliged when we asked the crowd. Assembled in a word cloud are their responses.

I’d like to point out one comment, “perfect documentation.” While yes, that will make an optimal response possible, documentation is not as valuable as practicing, continually identifying gaps, and being able to count on one another to think on the fly.
Don’t let perfect be the enemy of good.
Summary:
FEMA, NIST, CISA, and the White House often implore organizations to practice their response to cyber disasters. Some cyber insurance carriers are starting to require it.
The media and legal communities love to highlight those that don’t have an efficient IRP in place.
It’s impossible to understate the importance of practicing and adapting to different scenarios in disaster response.
Here are some takeaways:
Dos and Don’ts:
– Do practice and identify gaps in your response plan.
– Do communicate effectively with your teammates.
– Do share your thoughts and lessons learned after each tabletop scenario.
– Don’t let perfect be the enemy of good. Get started in some way today!
– Don’t rely solely on documentation or protocols. Teamwork and practice are key.
– Don’t ignore the feedback from the line of business participants. They own this too!
If you find yourself without the time or authority to execute an internal tabletop exercise or make progress closing your gaps, our Strategic Advisory team is at your disposal.
*Editor’s note*: We did run a second simulation – about an executive losing their mobile device out of the country on a Saturday while working on an M&A docket. Contact us if you’d like to benchmark how you’d handle that one!
If you have questions or would like assistance with your Incident Response strategy, please reach out to info@eGroup-us.com or complete the form below.
Looking for Guidance or Assistance with your Incident Response Strategy?
Contact our team today to learn how we can help.